
Bioinformatics
and Bio-logics
Eugene Thacker
Georgia Institute of Technology
eugene.thacker@lcc.gatech.edu
© 2003 Eugene Thacker.
All rights reserved.
- It is often noted that progress in biotechnology research
is as much a technological feat as a medical one. The
field of "bioinformatics" is exemplary here, since it is playing a
significant role in the various genome projects, the study of stem
cells, gene targeting and drug development, medical diagnostics, and
genetic medicine generally. Bioinformatics may simply be described as
the application of computer science to molecular biology research. The
development of biological databases (many of them online), gene
sequencing computers, computer languages (such as XML-based standards),
and a wide array of software tools (from pattern-matching algorithms to
data mining agents), are all examples of innovations by means of which
bioinformatics is transforming the traditional molecular biology
laboratory. Some especially optimistic reports on these developments have suggested that the "wet"
lab of traditional biology is being replaced by the "dry" lab of
"point-and-click biology."[1]

Figure 1: Production Sequencing Facility
at Department of Energy's Joint Genome Institute in Walnut Creek, CA - While current uses of bioinformatics are mostly pragmatic (technology-as-tool) and instrumental (forms of intellectual property and patenting), the issues which bioinformatics raises are simultaneously philosophical and technical. These issues have already begun to be explored in a growing body of critical work that approaches genetics and biotechnology from the perspective of language, textuality, and the various scripting tropes within molecular biology. The approach taken here, however, will be different. While critiques of molecular biology-as-text can effectively illustrate the ways in which bodies, texts, and contexts are always intertwined, I aim to interrogate the philosophical claims made by the techniques and technologies that molecular biotech designs for itself. Such an approach requires an inquiry into the materialist ontology that "informs" fields such as bioinformatics, managing as it does the relationships between the in vivo, the in vitro, and the in silico.
- Such questions have to do with how the intersection of genetic and computer codes is transforming the very definition of "the biological"--not only within bioinformatics but within molecular biotechnology as a whole. Thus, when we speak of the intersections of genetic and computer codes, we are not discussing the relationships between body and text, or material and semiotic registers, for this belies the complex ways in which "the body" has been enframed by genetics and biotechnology in recent years.
- What follows is a critical analysis of several types of
bioinformatics systems, emphasizing how the technical details of
software and programming are indissociable from these larger
philosophical questions of biological "life." The argument that will be
made is that bioinformatics is much more than simply the
"computerization" of genetics and molecular biology; it forms a set of
practices that instantiate ontological claims about the ways in which
the relationships between materiality and data, genetic and computer
codes, are being transformed through biotech research.
Bioinformatics in a Nutshell
- The first computer databases used for biological research were closely aligned with the first attempts to analyze and sequence proteins.[2] In the mid-1950s, the then-emerging field of molecular biology saw the first published research articles on DNA and protein sequences from a range of model organisms, including yeast, the roundworm, and the Drosophila fruit fly.[3] From a bioinformatics perspective, this research can be said to have been instrumental in identifying a unique type of practice in biology: the "databasing" of living organisms at the molecular level. Though these examples do not involve computers, they do adopt an informatic approach in which, using wet lab procedures, the organism is transformed into an organization of sequence data, a set of strings of DNA or amino acids.
- Because most of this sequence data was related to protein
molecules (structural data derived from X-ray crystallography), the
first computer databases for molecular biology were built in the 1970s
(Protein Data Bank) and 1980s (SWISS-PROT database).[4] Bioinformatics was, however, given its greatest
boost from the Human Genome Project (HGP) in its originary conception, a
joint Department of Energy (DoE) and National Institutes of Health (NIH) sponsored endeavor based in the U.S. and initiated in
1989-90.[5] The HGP went beyond the
single-study sequencing of a bacteria, or the derivation of structural
data of a single protein. It redefined the field, not only positing
a universality to the genome, but also implying that a knowledge of the
genome could occur only at this particular moment, when computing
technologies reached a level at which large amounts of data could be
dynamically archived and analyzed. Automated gene sequencing computers,
advanced robotics, high-capacity computer database arrays, computer
networking, and (often proprietary) genome analysis software were just
some of the computing technologies employed in the human genome project.
In a sense, the HGP put to itself the problem of both regarding the
organism itself as a database and porting that database from one
medium (the living cell) into another (the computer database).[6]
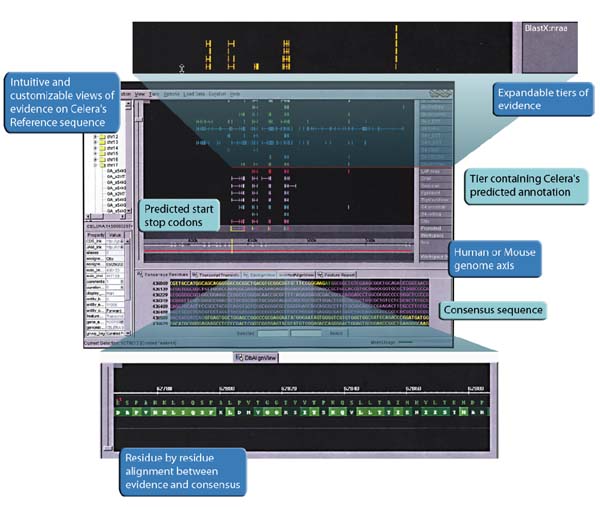
Figure 2: Commercial bioinformatics application by Celera Genomics - At this juncture it is important to make a brief historical aside, and that is that bioinformatics is unthinkable without a discourse concerning DNA-as-information. As Lily Kay has effectively shown, the notion of the "genetic code"--and indeed of molecular genetics itself--emerges through a cross-pollination with the discourses of cybernetics, information theory, and early computer science during the post-war era, long before computing technology was thought of as being useful to molecular biology research.[7] Though there was no definitive formulation of what exactly genetic "information" was (and is), the very possibility of an interdisciplinary influence itself conditions bioinformatics' possibility of later technically materializing the genome itself as a database.
- Against this discursive backdrop, we can make several points in
extending Kay's historiography in relation to contemporary
bioinformatics. One is that, while earlier paradigms in molecular
biology were, according to Kay, largely concerned with defining and
deciphering DNA as a "code," contemporary molecular genetics and biotech
research is predominantly concerned with the functionality of living
cells and genomes as computers in their own right.[8] What this means is that contemporary biotech is
constituted by both a "control principle" and a "storage principle,"
which are seen to inhere functionally within biological organization
itself. If the control principle derives from genetic engineering and
recombinant DNA techniques, the storage principle is derived from the
human genome project. Both can be seen to operate within bioinformatics
and biotech research today.[9]
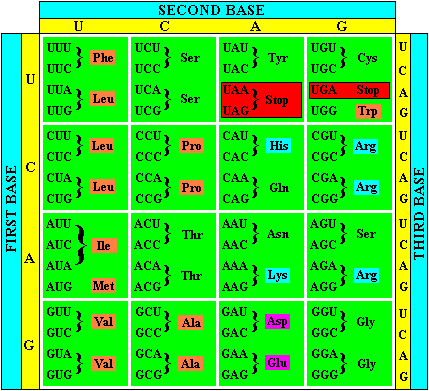
Figure 3: The genetic code.
Triplet codons each code for a particular amino acid. - To give an idea of what contemporary bioinformatics researchers
do, we can briefly consider one technique. Among the most common
techniques employed in current bioinformatics research is the sequence
alignment, a technique which can lead to the identification and
characterization of specific molecules (e.g., gene targeting for drug
development), and even the prediction of the production and interaction
of molecules (e.g., gene prediction for studying protein synthesis).[10] Also referred to as "pairwise
sequence alignment," this simply involves comparing one sequence (DNA or
protein code) against a database for possible matches or near-matches
(called "homologs"). Doing this involves an interactive pattern-matching
routine, compared against several "reading frames" (depending on where
one starts the comparison along the sequence), a task to which computer
systems are well attuned. Bioinformatics tools perform such
pattern-matching analyses through algorithms which accept an input
sequence, and then access one or more databases to search for close
matches.[11] What should be noted,
however, is that despite this breadth of expandability and application,
bioinformatics tools are often geared toward a limited number of ends:
the isolation of candidate genes or proteins for medical-genetic
diagnostics, drug development, or gene-based therapies.
Bio-logic
- However, if bioinformatics is simply the use of computer technologies to analyze strings, access online databases, and perform computational predictions, one question may beg asking: aren't we simply dealing with data, data that has very little to do with the "body itself"? In many senses we are dealing with data, and it is precisely the relation of that data to particularized bodies which bioinformatics materializes through its practices. We can begin to address this question of "just data" by asking another question: when we hear talk about "biological data" in relation to bioinformatics and related fields, what exactly is meant by this?
- On one level, biological data is indeed nothing but computer code. The majority of biological databases store not biological nucleic acids, amino acids, enzymes, or entire cells, but rather strings of data which, depending on one's perspective, are either abstractions, representations, or indices of actual biomolecules and cells. In computer programming terminology, "strings" are simply any linear sequence of characters, which may be numbers, letters, symbols, or combinations thereof. Programs that perform various string manipulations can carry out a wide array of operations based on combinatorial principles applied to the same string. The most familiar type of string manipulation takes place when we edit text. In writing email, for instance, the text we type into the computer must be encoded into a format that can be transmitted across a network. The phrase "in writing email, for instance" must be translated into a lower-level computer language of numbers, each group of numbers representing letters in the sequence of the sentence. At an even more fundamental level, those numbers must themselves be represented by a binary code of zeros and ones, which are themselves translated as pulses of light along a fiber optic cable (in the case of email) or within the micro-circuitry of a computer processor (in the case of word processing).
- In text manipulations such as writing email or word processing, a common encoding standard is known as ASCII, or the American Standard Code for Information Interchange. ASCII was established by the American Standards Association in the 1960s, along with the development of the Internet and the business mainframe computer, as a means of standardizing the translation of English-language characters on computers. ASCII is an "8-bit" code, in that a group of eight ones and zeros represents a certain number (such as "112"), which itself represents a letter (such as lower case "p"). Therefore, in the phrase "in writing email, for instance" each character--letters, punctuation, and spaces--is coded for by a number designated by the ASCII standard.[12]
- How does this relate to molecular biotechnology and the
biomolecular body? As we've noted, most biological databases, such as
those housing the human genome, are really just files which contain long
strings of letters: As, Ts, Cs, and Gs, in the case of a nucleotide
database. When news reports talk about the "race to map the human
genome," what they are actually referring to is the endeavor to convert
the order of the sequence of DNA molecules in the chromosomes in the
cell to a database of digital strings in a computer. Although the
structural properties of DNA are understood to play an important part in
the processes of transcription and translation in the cell, for a number
of years the main area of focus in genetics and biotech has, of course,
been on DNA and "genes." In this focus, of primary concern is how the
specific order of the string of DNA sequence plays a part in the
production of certain proteins, or in the regulation of other genes.
Because sequence is the center of attention, this also means that, for
analytical purposes, the densely coiled, three-dimensional, "wet" DNA in
the cell must be converted into a linear string of data. Since
nucleotide sequences have traditionally been represented by the letter
of their bases (Adenine, Cytosine, Guanine, Thymine), ASCII provides a
suitable encoding scheme for long strings of letters. To make this
relationship clearer, we can use a table:
DNA A T C G ASCII 65 84 67 71 Binary 01000001 01010100 01000011 01000111 - In the same way that English-language characters are encoded by ASCII, the representational schemes of molecular biology are here also encoded as ASCII numbers, which are themselves binary digits. At the level of binary digits, the level of "machine language," the genetic code is therefore a string of ones and zeros like any other type of data. Similarly, a database file containing a genetic sequence is read from ASCII numbers and presented as long linear strings of four letters (and can even be opened in a word processing application). Therefore, when, in genetics textbooks, we see DNA diagrammed as a string of beads marked "A-T" or "C-G," what we are looking at is both a representation of a biomolecule and a schematic of a string of data in a computer database.
- Is that all that biological data is? If we take this
approach--that is, that biological data is a quantitative abstraction of
a "real" thing, a mode of textuality similar to language itself--then we
are indeed left with the conclusion that biological data, and
bioinformatics, is nothing more than an abstraction of the real by the
digital, a kind of linguistic system in which letters-molecules signify
the biological phenotype. While this may be the case from a purely
technical--and textual--perspective, we should also consider the kinds
of philosophical questions which this technical configurations elicits.
That is, if we leave, for a moment, the epistemological and linguistic
debate of the real vs. the digital, the thing-itself vs. its
representation, and consider not "objects" but rather relationships, we
can see that "biological data" is more than a binary sign-system. Many
of the techniques within bioinformatics research appear to be more
concerned with function than with essence; the question a
bioinformatician asks is not "what it is," but rather "how it works."
Take, for example, a comment from the Bioinformatics.org website, which is
exemplary of a certain perspective on biological data:
It is a mathematically interesting property of most large biological molecules that they are polymers; ordered chains of simpler molecular modules called monomers....Many monomer molecules can be joined together to form a single, far larger, macromolecule which has exquisitely specific informational content and/or chemical properties. According to this scheme, the monomers in a given macromolecule of DNA or protein can be treated computationally as letters of an alphabet, put together in pre-programmed arrangements to carry messages or do work in a cell. [13]
- What is interesting about such perspectives is that they suggest that the notion of biological data is not about the ways in which a real (biological) object may be abstracted and represented (digitally), but instead is about the ways in which certain "patterns of relationships" can be identified across different material substrates, or across different platforms. We still have the code conversion from the biological to the digital, but rather than the abstraction and representation of a "real" object, what we have is the cross-platform conservation of specified patterns of relationships. These patterns of relationships may, from the perspective of molecular biology, be elements of genetic sequence (such as base pair binding in DNA), molecular processes (such as translation of RNA into amino acid chains), or structural behaviors (such as secondary structure folding in proteins). The material substrate may change (from a cell to a computer database), and the distinction between the wet lab and the dry lab may remain (wet DNA, dry DNA), but what is important for the bioinformatician is how "biological data" is more than just abstraction, signification, or representation. This is because the biological data in computer databases are not merely there for archival purposes, but as data to be worked on, data which, it is hoped, will reveal important patterns that may have something to say about the genetic mechanisms of disease.
- While a simulation of DNA transcription and translation may be constructed on a number of software platforms, it is noteworthy that the main tools utilized for bioinformatics begin as database applications (such as Unix-based administration tools). What these particular types of computer technologies provide is not a more perfect representational semblance, but a medium-specific context, in which the "logic" of DNA can be conserved and extended in various experimental conditions. What enables the practices of gene or protein prediction to occur at all is a complex integration of computer and genetic codes as functional codes. From the perspective of bioinformatics, what must be conserved is the pattern of relationships that is identified in wet DNA (even though the materiality of the medium has altered). A bioinformatician performing a multiple sequence alignment on an unknown DNA sample is interacting not just with a computer, but with a "bio-logic" that has been conserved in the transition from the wet lab to the dry lab, from DNA in the cell to DNA in the database.
- In this sense, biological data can be described more accurately than as a sign system with material effects. Biological data can be defined as the consistency of a "bio-logic" across material substrates or varying media. This involves the use of computer technologies that conserve the bio-logic of DNA (e.g., base pair complementarity, codon-amino acid relationships, restriction enzyme splice sites) by developing a technical context in which that bio-logic can be recontextualized in novel ways (e.g., gene predictions, homology modeling). Bioinformatics is, in this way, constituted by a challenge, one that is as much technical as it is theoretical: it must manage the difference between genetic and computer codes (and it is this question of the "difference" of bioinformatics that we will return to later).
- On a general level, biotech's regulation of the relationship between genetic codes and computer codes would seem to be mediated by the notion of "information"--a principle that is capable of accommodating differences across media. This "translatability" between media--in our case between genetic codes and computer codes--must then also work against certain transformations that might occur in translation. Thus the condition of translatability (from genetic to computer code) is not only that linkages of equivalency are formed between heterogeneous phenomena, but also that other kinds of (non-numerical, qualitative) relationships are prevented from forming, in the setting-up of conditions whereby a specific kind of translation can take place.[14]
- Thus, for bioinformatics approaches, the technical challenge is
to effect a "translation without transformation," to preserve the
integrity of genetic data, irrespective of the media through which that
information moves. Such a process is centrally concerned with a denial
of the transformative capacities of different media and informational
contexts themselves. For bioinformatics, the medium is not the message;
rather, the message--a genome, a DNA sample, a gene--exists in a
privileged site of mobile abstraction that must be protected from the
heterogeneous specificities of different media platforms in order to
enable the consistency of a bio-logic.
BLASTing the Body
- We can take a closer look at how the bio-logic of bioinformatics operates by considering the use of an online software tool called "BLAST," and the technique of pairwise sequence alignment referred to earlier. Again, it is important to reiterate the approach being taken here. We want to concentrate on the technical details to the extent that those details reveal assumptions that are extra-technical, which are, at their basis, ontological claims about biological "information." This will therefore require--in the case of BLAST--a consideration of software design, usability, and application.
- BLAST is one of the most commonly used bioinformatics tools. It stands for "Basic Local Alignment Search Tool" and was developed in the 1990s at the National Center for Biotechnology Information (NCBI).[15] BLAST, as its full name indicates, is a set of algorithms for conducting analyses on sequence alignments. The sequences can be nucleotide or amino acid sequences, and the degree of specificity of the search and analysis can be honed by BLAST's search parameters. The BLAST algorithm takes an input sequence and then compares that sequence to a database of known sequences (for instance, GenBank, EST databases, restriction enzyme databases, protein databases, etc.). Depending on its search parameters, BLAST will then return output data of the most likely matches. A researcher working with an unknown DNA sequence can use BLAST in order to find out if the sequence has already been studied (BLAST includes references to research articles and journals) or, if there is not a perfect match, what "homologs" or close relatives a given sequence might have. Either kind of output will tell a researcher something about the probable biochemical characteristics and even function of the test sequence. In some cases, such searches may lead to the discovery of novel sequences, genes, or gene-protein relationships.
- Currently, the NCBI holds a number of different sequence
databases, all of which can be accessed using different versions of
BLAST.[16] When BLAST first
appeared, it functioned as a stand-alone Unix-based application. With
the introduction of the Web into the scientific research community in
the early 1990s, however, BLAST was ported to a Web-ready interface
front-end and a database-intensive back-end.[17]
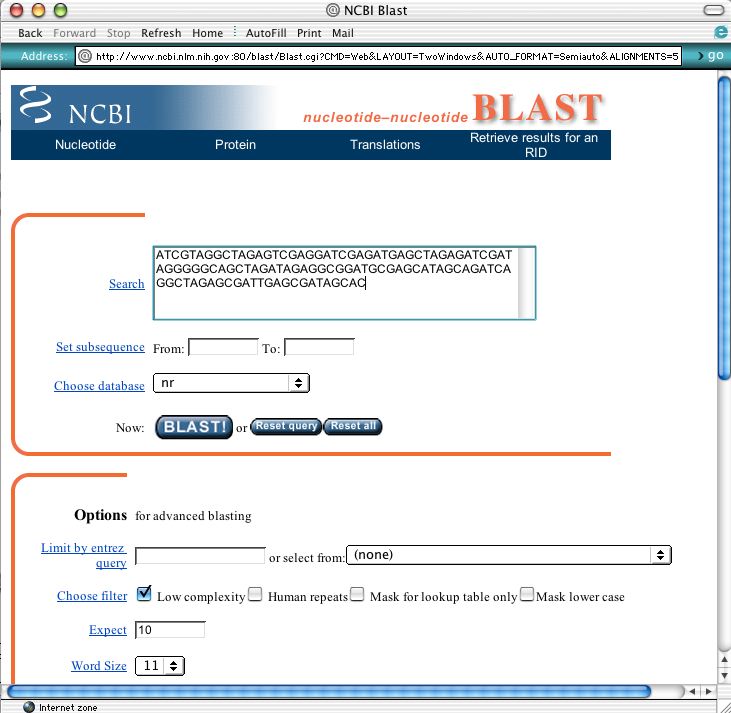
Figure 4: Sequence search interface for BLAST. - BLAST has become somewhat of a standard in bioinformatics because it generates a large amount of data from a
relatively straightforward task. Though sequence alignments can sometimes be computationally intensive, the basic principle
is simple: comparison of strings. First, a "search domain" is defined for BLAST, which may be the selection of or
within a particular database. This constrains BLAST's domain of activity, so that it doesn't waste time searching for
matches in irrelevant data sets. Then an input sequence is "threaded" through the search domain. The BLAST algorithm
searches for closest matches based on a scoring principle. When the search is complete, the highest scoring hits are
kept and ranked. Since the hits are known sequences from the database, all of their relevant characterization data can
be easily accessed. Finally, for each hit, the relevant bibliographical data is also retrieved. A closer look at the
BLAST algorithm shows how it works with biological data:

Figure 5: The BLAST search algorithm. - In considering the BLAST algorithm, it is important to keep in mind the imperative of "bio-logic" in bioinformatics research. BLAST unites two crucial aspects of bioinformatics: the ability to flexibly archive and store biological data in a computer database, and the development of diversified tools for accessing and interacting with that database (the control and storage principles mentioned earlier). Without a database of biological data--or rather, a database of bio-logics--bioinformatics tools are nothing more than simulation. Conversely, without applications to act on the biological data in the database, the database is nothing more than a static archive. Bioinformatics may be regarded as this ongoing attempt to integrate seamlessly the control and storage principles across media, whether in genetically engineered biomolecules or in online biological databases.
- Though databases are not, of course, exclusive to bioinformatics, the BLAST algorithm is tailored to the bio-logic of nucleotide and protein sequence.[18] The bio-logic of base pair complementarity among sequential combinations of four nucleotides (A-T; C-G) is but one dimension of the BLAST algorithm. Other, more complex aspects, such as the identification of repeat sequences, promoter and repressor regions, and transcription sites, are also implicated in BLAST's biological algorithm. What BLAST's algorithm conserves is this pattern of relationships, this bio-logic which is seen to inhere in both the chromosomes and the database.
- BLAST not only translates the biomolecular body by conserving this bio-logic across material substrates; in this move from one medium to another, it also extends the control principle to enable novel formulations of biomolecules not applicable to the former, "wet" medium of the cell's chromosomes. One way in which BLAST does this is through the technique of the "search query." The "query" function is perhaps most familiar to the kinds of searches carried out on the Web using one of many "search engines," each of which employs different algorithms for gathering, selecting, and ordering data from the Web.[19] BLAST does not search the Web but rather performs user-specified queries on biological databases, bringing together the control and storage principles of bioinformatics. At the NCBI website, the BLAST interface contains multiple input options (text fields for pasting a sequence or buttons for loading a local sequence file) which make use of special scripts to deliver the input data to the NCBI server, where the query is carried out. These scripts, known as "CGI" or "Common Gateway Interface" scripts, are among the most commonly used scripts on the Web for input data on web pages. CGI scripts run on top of HTML web pages and form a liason for transmitting specific input data between a server computer and a client's computer.[20] A BLAST query will take the input sequence data and send it, along with instructions for the search, to the server. The BLAST module on the NCBI server will then accept the data and run its alignments as specified in the CGI script. When the analysis is finished, the output data is collected, ordered, and formatted (as a plain-text email or as HTML).
- BLAST queries involve an incorporation of "raw" biological data
that is ported through the medium (in this case, computer network code)
so that it can be processed in a medium-specific context in which it
"makes sense." The output is more than mere bits, signs, or letters; the
output is a configured bio-logic that is assumed to exist above the
domain of specific substance (carbon or silicon). From a
philosophical-technical perspective, BLAST is not so much a sequence
alignment tool as an exemplary case of the way bioinformatics translates a relationship between discrete entities (DNA,
RNA, and synthesis of amino acids in the cell) across material
substrates, with an emphasis on the ways in which the control principle
may extend the dimensions of the biological data.
Translation without Transformation
- In different ways, tools such as BLAST constantly attempt to manage the difference between genetic and computer codes through modes of regulating the contexts in which code conversions across varying media take place.
- BLAST also aims for a transparent translation of code across different contexts; such software systems are primarily concerned with providing bio-logical conversions between output data that can be utilized for analysis and further molecular biology research. Presenting an output file that establishes relationships between a DNA sequence, a multiple pairwise alignment, and other related biomolecular information, is a mode of translating between data types by establishing relations between them that are also biological relations (e.g., base pair complementarity, gene expression). The way in which this is done is, of course, via a strictly "non-biological" operation which is the correlation of data as data (as string manipulation, as in pairwise alignments). In order to enable this technical and biological translation, BLAST must operate as a search tool in a highly articulated manner. A "structured query language" in this case means much more than simply looking up a journal author, title of a book, or subject heading. It implies a whole epistemology, from the molecular biological research point of view. What can be known and what kinds of queries can take place are intimately connected with tools such as BLAST. For this reason, such tools are excellent as "gene finders," but they are poor at searching and analyzing nested, highly-distributed biopathways in a cell. The instability in such processes as cell regulation and metabolism is here stabilized by aligning the functionalities of the materiality of the medium (in this case, computer database query software) with the constrained organization of biological data along two lines: first in a database, and secondly as biological components and processes (DNA, RNA, ESTs, amino acids, etc.).
- In the example of BLAST, the interplay of genetic and computer codes is worked upon so that their relationship to each other is transparent. In other words, when looked at as "biomedia"--that is, as the technical recontextualiztion of the biological domain--BLAST reinforces the notion of media as transparent.[21] The workings of a BLAST search query disappear into the "back-end," so that the bio-logic of DNA sequence and structure may be brought forth as genetic data in itself. However, as we've seen, this requires a fair amount of work in recontextualizing and reconfiguring the relations between genetic and computer codes; the regulatory practices pertaining to the fluid translation of types of biological data all work toward this end.
- The amount of recontextualizing that is required, the amount of technical reconfiguration needed, is therefore proportionately related to the way the bio-logic of DNA sequence and structure is presented. In a BLAST query and analysis, the structure and functionalities of computer technology are incorporated as part of the "ontology" of the software, and the main reason this happens is so that novel types of bio-logic can become increasingly self-apparent: characteristics that are "biological" but that could also never occur in the wet lab (e.g., multiple pairwise alignments, gene prediction, multiple-database queries).
- This generates a number of tensions in how the biomolecular body is reconceptualized in bioinformatics. One such tension is in how translation without transformation becomes instrumentalized in bioinformatics practices. On the one hand, a majority of bioinformatics software tools make use of computer and networking technology to extend the practices of the molecular biology lab. In this, the implication is that computer code transparently brings forth the biological body in novel contexts, thereby producing novel means of extracting data from the body. Within this infrastructure is also a statement about the ability of computer technology to bring forth, in ever greater detail, the bio-logic inherent in the genome, just as it is in the biological cell. The code can be changed, and the body remains the same; the same bio-logic of a DNA sequence in a cell in a petri dish is conserved in an online genome database.
- On the other hand, there is a great difference in the fact that bioinformatics doesn't simply reproduce the wet biology lab as a perfect simulation. Techniques such as gene predictions, database comparisons, and multiple sequence analysis generate biomolecular bodies that are specific to the medium of the computer.[22] The newfound ability to perform string manipulations, database queries, modeling of data, and to standardize markup languages also means that the question of "what a body can do" is extended in ways specific to the medium.[23] When we consider bioinformatics practices that directly relate (back) to the wet lab (e.g., rational drug design, primer design, genetic diagnostics), this instrumentalization of the biomolecular body becomes re-materialized in significant ways. Change the code, and you change the body. A change in the coding of a DNA sequence in an online database can directly affect the synthesis of novel compounds in the lab.
- As a way of elaborating on this tension, we can further elaborate the bio-logics of bioinformatics along four main axes.
- The first formulation is that of equivalency between genetic and computer codes. As mentioned previously, the basis for this formulation has a history that extends back to the post-war period, in which the discourses of molecular biology and cybernetics intersect, culminating in what Francis Crick termed "the coding problem." [24] In particular, gene sequencing (such as Celera's "whole genome shotgun sequencing" technique) offers to us a paradigmatic example of how bioinformatics technically establishes a condition of equivalency between genetic and computer codes.[25] If, so the logic goes, there is a "code" inherent in DNA--that is, a pattern of relationships which is more than DNA's substance--then it follows that that code can be identified, isolated, and converted across different media. While the primary goal of this procedure is to sequence an unknown sample, what genome sequencing must also accomplish is the setting up of the conditions through which an equivalency can be established between the wet, sample DNA, and the re-assembled genome sequence that is output by the computer. That is, before any of the more sophisticated techniques of bioinformatics or genomics or proteomics can be carried out, the principles for the technical equivalency between genetic and computer codes must be articulated.
- Building upon this, the second formulation is that of a back-and-forth mobility between genetic and computer codes. That is, once the parameters for an equivalency can be established, the conditions are set for enabling conversions between genetic and computer codes, or for facilitating their transport across different media. Bioinformatics practices, while recognizing the difference between substance and process, also privilege another view of genetic and computer codes, one based on identified patterns of relationships between components--for instance, the bio-logic of DNA's base pair binding scheme (A-T; C-G), or the identification of certain polypeptide chains with folding behaviors (amino acid chains that make alpha-helical folds). These well-documented characteristics of the biomolecular body become, for bioinformatics, more than some "thing" defined by its substance; they become a certain manner of relating components and processes.
- The mobility between genetic and computer codes is more than the mere digitization of the former by the latter. What makes DNA in a plasmid and DNA in a database the "same"? A definition of what constitutes the biological in the term "biological data." Once the biological domain is approached as this bio-logic, as these identified and selected patterns of relationships, then, from the perspective of bioinformatics--in principle at least--it matters little whether that DNA sample resides in a test tube or a database. Of course, there is a similar equivalency in the living cell itself, since biomolecules such as proteins can be seen as being isomorphic with each other (differing only in their "folds"), just as a given segment of DNA can be seen as being isomorphic in its function within two different biopathways (same gene, different function). Thus the mobility between genetic and computer codes not only means that the "essential data" or patterns can be translated from wet to dry DNA. It also means that bioinformatics practices such as database queries are simultaneously algorithmic and biological.
- Beyond these two first formulations are others that develop functionalities based on them. One is a situation in which data accounts for the body. In examples relating to genetic diagnostics, data does not displace or replace the body, but rather forms a kind of index to the informatic muteness of the biological body--DNA chips in medical genetics, disease profiling, pre-implantation screening for IVF, as well as other, non-biological uses, all depend to some extent of bioinformatics techniques and technologies. The examples of DNA chips in medical contexts redefine the ways in which accountability takes place in relation to the physically-present, embodied subject. While its use in medicine is far from being common, genetic testing and the use of DNA chips are, at least in concept integrating themselves into the fabric of medicine, where an overall genetic model of disease is often the dominant approach to a range of genetic-related conditions, from Alzheimer's to diabetes to forms of cancer.[26] However, beneath these issues is another set of questions that pertain to the ways in which a mixture of genetic and computer codes gives testimony to the body, and through its data-output, accounts for the body in medical terms (genetic patterns, identifiable disease genes, "disease predispositions").[27] Again, as with the establishing of an equivalency, and the effecting of a mobility, the complex of genetic and computer codes must always remain biological, even though its very existence is in part materialized through the informatic protocols of computer technology. In a situation where data accounts for the body, we can also say that a complex of genetic and computer codes makes use of the mobility between genetic and computer codes, to form an indexical description of the biological domain, as one might form an index in a database. But, it should be reiterated that this data is not just data, but a conservation of a bio-logic, a pattern of relationships carried over from the patient's body to the DNA chip to the computer system. It is in this sense that data not only accounts for the body, but that the data (a complex of genetic and computer codes) also identifies itself as biological.
- Finally, not only can data account for the body, but the body can be generated through data. We can see this type of formulation occurring in practices that make use of biological data to effect changes in the wet lab, or even in the patient's body. Here we can cite the field known as "pharmacogenomics," which involves the use of genomic data to design custom-tailored gene-based and molecular therapies.[28] Pharmacogenomics moves beyond the synthesis of drugs in the lab and relies on data from genomics in its design of novel compounds. It is based not on the diagnostic model of traditional pharmaceuticals (ameliorating symptoms), but rather on the model of "preventive medicine" (using predictive methods and genetic testing to prevent disease occurrence or onset). This not only means that pharmacogenomic therapies will be custom-designed to each individual patient's genome, but also that the therapies will operate for the long-term, and in periods of health as well as of disease.
- What this means is that "drugs" are replaced by "therapies," and
the synthetic is replaced by the biological, but a biological that is preventive and
not simply curative. The image of the immune
system that this evokes is based on more than the correction of
"error" in the body. Rather, it is based on the principles of
biomolecular and biochemical design, as applied to the optimization of
the biomolecular body of the patient. At an even more specific level,
what is really being "treated" is not so much the patient but the
genome. At the core of pharmacogenomics is the notion that a
reprogramming of the "software" of the genome is the best route to
preventing the potential onset of disease in the biological body. If the
traditional approaches of immunology and the use of vaccines are based on
synthesizing compounds to counter certain proteins, the approach of
pharmacogenomics is to create a context in which a reprogramming will enable the body biologically to produce the
needed antibodies itself, making the "medium" totally transparent. The
aim of pharmacogenomics is, in a sense, not to make any drugs at all,
but to enable the patient's own genome to do so.[29]
Virtual Biology?
- To summarize: the equivalency, the back-and-forth mobility, the accountability, and the generativity of code in relation to the body are four ways in which the bio-logic of the biomolecular body is regulated. As we've seen, the tensions inherent in this notion of biological information are that sometimes the difference between genetic and computer codes is effaced (enabling code and file conversions), and at other times this difference is referred back to familiar dichotomies (where flesh is enabled by data, biology by technology). We might abbreviate by saying that, in relation to the biomolecular body, bioinformatics aims to realize the possibility of the body as "biomedia."
- The intersection of biotech and infotech goes by many names--bioinformatics, computational biology, virtual biology. This last term is especially noteworthy, for it is indicative of the kinds of philosophical assumptions within bioinformatics that we have been querying. A question, then: is biology "virtual"? Certainly from the perspective of the computer industry, biology is indeed virtual, in the sense of "virtual reality," a computer-generated space within which the work of biology may be continued, extended, and simulated. Tools such as BLAST, molecular modeling software, and genome sequencing computers are examples of this emerging virtual biology. From this perspective, a great deal of biotech research--most notably the various genome efforts--is thoroughly virtual, meaning that it has become increasingly dependent upon and integrated with computing technologies.
- But if we ask the question again, this time from the philosophical standpoint, the question changes. Asking whether or not biology is philosophically virtual entails a consideration of how specific fields such as bioinformatics conceptualize their objects of study in relation to processes of change, difference, and transformation. If, as we've suggested, bioinformatics aims for the technical condition (with ontological implications) of "translation without transformation," then what is meant by "transformation"? As we've seen above, transformation is related technically to the procedures of encoding, recoding, and decoding genetic information that constitute a bio-logic. What makes this possible technically is a twofold conceptual articulation: there is something in both genetic and computer codes that enables their equivalency and therefore their back-and-forth mobility (DNA sampling, analysis, databasing). This technical-conceptual articulation further enables the instrumentalization of genetic and computer codes as being mutually accountable (genetic disease predisposition profiling) and potentially generative or productive (genetically based drug design or gene therapies).
- Thus, the transformation in this scenario, whose negation forms the measure of success for bioinformatics, is related to a certain notion of change and difference. To use Henri Bergson's distinction, the prevention of transformation in bioinformatics is the prevention of a difference that is characterized as quantitative (or "numerical") and extensive (or spatialized).[30] What bioinformatics developers want to prevent is any difference (distortion, error, noise) between what is deemed to be information as one moves from an in vitro sample to a computer database to a human clinical trial for a gene-based therapy. This means preserving information as a quantifiable, static unit (DNA, RNA, protein code) across variable media and material substrates.
- However, difference in this sense--numerical, extensive difference--is not the only kind of difference. Bergson also points to a difference that is, by contrast, qualitative ("non-numerical") and intensive (grounded in the transformative dynamics of temporalization, or "duration"). Gilles Deleuze has elaborated Bergson's distinction by referring to the two differences as external and internal differences, and has emphasized the capacity of the second, qualitative, intensive difference continually to generate difference internally--a difference from itself, through itself.[31]
- How would such an internal--perhaps self-organizing--difference
occur? A key concept in understanding the two kinds of differences is
the notion of "the virtual," but taken in its philosophical and not
technical sense. For Bergson (and Deleuze), the virtual and actual form
one pair, contrasted to the pair of the possible and the real. The
virtual/actual is not the converse of the possible/real; they are two
different processes by which material-energetic systems are organized.
As Deleuze states:
From a certain point of view, in fact, the possible is the opposite of the real, it is opposed to the real; but, in quite a different opposition, the virtual is opposed to the actual. The possible has no reality (although it may have an actuality); conversely, the virtual is not actual, but as such possesses a reality. (Bergsonism 96)
- We might add another variant: the possible is negated by the real (what is real is no longer possible because it is real), and the virtual endures in the actual (what is actual is not predetermined in the virtual, but the virtual as a process is immanent to the actual). As Deleuze notes, the possible is that which manages the first type of difference, through resemblance and limitation (out of a certain number of possible situations, one is realized). By contrast, the virtual is itself this second type of difference, operating through divergence and proliferation.
- With this in mind, it would appear that bioinformatics--as a technical and conceptual management of the material and informatic orders--prevents one type of difference (as possible transformation) from being realized. This difference is couched in terms derived from information theory and computer science and is thus weighted toward a more quantitative, measurable notion of information (the first type of quantitative, extensive difference). But does bioinformatics--as well as molecular genetics and biology--also prevent the second type of qualitative, intensive, difference? In a sense it does not, because any analysis of qualitative changes in biological information must always be preceded in bioinformatics by an analysis of quantitative changes, just as genotype may be taken as causally prior to phenotype in molecular genetics. But in another sense the question cannot be asked, for before we inquire into whether or not bioinformatics includes this second type of difference in its aims (of translation without transformation), we must ask whether or not such a notion of qualitative, intensive difference exists in bioinformatics to begin with.
- This is why we might question again the notion of a "virtual biology." For, though bioinformatics has been developing at a rapid rate in the past five to ten years (in part bolstered by advances in computer technology), there are still a number of extremely difficult challenges in biotech research which bioinformatics faces. Many of these challenges have to do with biological regulation: cell metabolism, gene expression, and intra- and inter-cellular signaling.[32] Such areas of research require more than discrete databases of sequence data, they require thinking in terms of distributed networks of processes which, in many cases, may change over time (gene expression, cell signaling, and point mutations are examples).
- In its current state, bioinformatics is predominantly geared toward the study of discrete, quantifiable systems that enable the identification of something called genetic information (via the four-fold process of bio-logic). In this sense bioinformatics works against the intervention of one type of difference, a notion of difference that is closely aligned to the traditions of information theory and cybernetics. But, as Bergson reminds us, there is also a second type of difference which, while being amenable to quantitative analysis, is equally qualitative (its changes are not of degree, but of kind) and intensive (in time, as opposed to the extensive in space). It would be difficult to find this second kind of difference within bioinformatics as it currently stands. However, many of the challenges facing bioinformatics--and biotech generally--imply the kinds of transformations and dynamics embodied in this Bergsonian-Deleuzian notion of difference-as-virtual.
- It is in this sense that a "virtual biology" is not a conceptual impossibility, given certain contingencies. If bioinformatics is to accommodate the challenges put to it by the biological processes of regulation (metabolism, gene expression, signaling), then it will have to consider a significant re-working of what counts as "biological information." As we've pointed out, this reconsideration of information will have to take place on at least two fronts: that of the assumptions concerning the division between the material and informatic orders (genetic and computer codes, biology and technology, etc.), and that of the assumptions concerning material-informatic orders as having prior existence in space, and secondary existence in duration (molecules first, then interactions; objects first, then relations; matter first, then force).[33] The biophilosophy of Bergson (and of Deleuze's reading of Bergson) serves as a reminder that, although contemporary biology and biotech are incorporating advanced computing technologies as part of their research, this does not necessarily mean that the informatic is "virtual."
Point-and-Click Biology
School of Literature, Communication, and Culture
Georgia Institute of Technology
eugene.thacker@lcc.gatech.edu
Talk Back
COPYRIGHT (c) 2003 Eugene Thacker. READERS MAY USE
PORTIONS OF THIS WORK IN ACCORDANCE WITH THE FAIR USE PROVISIONS OF U.S.
COPYRIGHT LAW. IN ADDITION, SUBSCRIBERS AND MEMBERS OF SUBSCRIBED
INSTITUTIONS MAY
USE THE ENTIRE WORK FOR ANY INTERNAL NONCOMMERCIAL PURPOSE BUT, OTHER THAN
ONE COPY SENT BY EMAIL, PRINT OR FAX TO ONE PERSON AT ANOTHER LOCATION FOR
THAT INDIVIDUAL'S PERSONAL USE, DISTRIBUTION OF THIS ARTICLE OUTSIDE OF A
SUBSCRIBED INSTITUTION WITHOUT EXPRESS WRITTEN PERMISSION FROM EITHER THE
AUTHOR OR THE JOHNS HOPKINS UNIVERSITY PRESS IS EXPRESSLY FORBIDDEN.
THIS ARTICLE AND OTHER CONTENTS OF THIS ISSUE ARE
AVAILABLE FREE OF CHARGE UNTIL RELEASE OF THE NEXT ISSUE. A
TEXT-ONLY ARCHIVE OF THE JOURNAL IS ALSO AVAILABLE FREE OF CHARGE.
FOR FULL HYPERTEXT ACCESS TO BACK ISSUES, SEARCH UTILITIES, AND OTHER
VALUABLE FEATURES, YOU OR YOUR INSTITUTION MAY SUBSCRIBE TO
PROJECT MUSE, THE
ON-LINE JOURNALS PROJECT OF THE
JOHNS HOPKINS UNIVERSITY PRESS.
Notes
1. For non-technical summaries of bioinformatics see the articles by Howard, Goodman, Palsson, and Emmett. As one researcher states, bioinformatics is specifically "the mathematical, statistical and computing methods that aim to solve biological problems using DNA and amino acid sequences and related information" (from bioinformatics.org).
2.The use of computers in biology and life science research is certainly nothing new, and, indeed, an informatic approach to studying biological life may be seen to extend back to the development of statistics, demographics, and the systematization of health records during the eighteenth and nineteenth centuries. This proto-informatic approach to the biological/medical body can be seen in Foucault's work, as well as in medical-sociological analyses inspired by him. Foucault's analysis of the medical "gaze" and nosology's use of elaborate taxonomic and tabulating systems are seen to emerge alongside the modern clinic's management and conceptualization of public health. Such technologies are, in the later Foucault, constitutive of the biopolitical view, in which power no longer rules over death, but rather impels life, through the institutional practices of the hospital, health insurances, demographics, and medical practice generally. For more see Foucault's The Birth of the Clinic, as well as "The Birth of Biopolitics."
3. Molecular biochemist Fred Sanger published a report on the protein sequence for bovine insulin, the first publication of sequencing research of this kind. This was accompanied a decade later by the first published paper on a nucleotide sequence, a type of RNA from yeast. See Sanger, "The Structure of Insulin," and Holley, et al., "The Base Sequence of Yeast Alanine Transfer RNA." A number of researchers also began to study the genes and proteins of model organisms (often bacteria, roundworms, or the Drosophila fruit fly) not so much from the perspective of biochemical action, but from the point of view of information storage. For an important example of an early database-approach, see Dayhoff et al., "A Model for Evolutionary Change in Proteins."
4.This, of course, was made possible by the corresponding advancements in computer technology, most notably in the PC market. See Abola, et al., "Protein Data Bank," and Bairoch, et al. "The SWISS-PROT Protein Sequence Data Bank."
5. Initially the HGP was funded by the U.S. Department of Energy and National Institute of Health, and had already begun forming alliances with European research institutes in the late 1980s (which would result in HUGO, or the Human Genome Organization). As sequencing endeavors began to become increasingly distributed to selected research centers and/or universities in the U.S. and Europe, the DoE's involvement lessened, and the NIH formed a broader alliance, the International Human Genome Sequencing Effort, with the main players being MIT's Whitehead Institute, the Welcome Trust (UK), Stanford Human Genome Center, and the Joint Genome Institute, among many others. This broad alliance was challenged when the biotech company Celera (then The Institute for Genome Research) proposed its own genome project funded by the corporate sector. For a classic anthology on the genome project, see the anthology The Code of Codes, edited by Kevles and Hood. For a popular account see Matt Ridley's Genome.
6. In this context it should also be stated that bioinformatics is also a business, with a software sector that alone has been estimated to be worth $60 million, and many pharmaceutical companies outsourcing more than a quarter of their R&D to bioinformatics start-ups. See the Silico Research Limited report "Bioinformatics Platforms," at: <http://www.silico-research.com>.
7. See Kay's book Who Wrote the Book of Life? A History of the Genetic Code, as well as her essay "Cybernetics, Information, Life: The Emergence of Scriptural Representations of Heredity."
8. Kay provides roughly three discontinuous, overlapping periods in the history of the genetic code--a first phase marked by the trope of "specificity" during the early part of the twentieth century (where proteins were thought to contain the genetic material), a second "formalistic" phase marked by the appropriation of "information" and "code" from other fields (especially Francis Crick's formulation of "the coding problem"), and a third, "biochemical" phase during the 1950s and 60s, in which the informatic trope is extended, such that DNA is not only a code but a fully-fledged "language" (genetics becomes cryptography, as in Marshall Nirenberg and Heinrich Matthai's work on "cracking the code" of life).
9. Herbert Boyer and Stanley Cohen's recombinant DNA research had demonstrated that DNA could not only be studied, but be rendered as a technology. The synthesis of insulin--and the patenting of its techniques--provides an important proof-of-concept for biotechnology's control principle in this period. For an historical overview of the science and politics of recombinant DNA, see Aldridge, The Thread of Life. For a popular critical assessment, see Ho, Genetic Engineering. On recombinant DNA, see the research articles by Cohen, et al. and Chang, et al. The work of Cohen and Boyer's teams resulted in a U.S. patent, "Process For Producing Biologically Functional Molecular Chimeras" (#4237224), as well as the launching of one of the first biotech start-ups, Genentech, in 1980. By comparison, the key players in the race to map the human genome were not scientists, but supercomputers, databases, and software. During its inception in the late 1980s, the DoE's Human Genome Project signaled a shift from a control principle to a "storage principle." This bioinformatic phase is increasingly suggesting that biotech and genetics research is non-existent without some level of data storage technology. Documents on the history and development of the U.S. Human Genome Project can be accessed through its website, at <http://www.ornl.gov/hgmis>.
10. At the time of this writing, molecular biologists can perform five basic types of research using bioinformatics tools: digitization (encoding biological samples), identification (of an unknown sample), analysis (generating data on a sample), prediction (using data to discover novel molecules), and visualization (modeling and graphical display of data).
11. Bioinformatics tools can be as specific or as general as a development team wishes. Techniques include sequence assembly (matching fragments of sequence), sequence annotation (notes on what the sequence means), data storage (in dynamically updated databases), sequence and structure prediction (using data on identified molecules), microarray analysis (using biochips to analyze test samples), and whole genome sequencing (such as those on the human genome). For more on the technique of pairwise sequence alignment see Gibas and Gambeck's technical manual, Developing Bioinformatics Computers Skills, and Baxevanis, et al., eds., Bioinformatics: A Practical Guide to the Analysis of Genes and Proteins. For a hacker-hero's narrative, see Lincoln Stein's paper "How PERL Saved the Human Genome Project."
12. See MacKenzie, Coded Character Sets.
13. At <http://www.bioinformatics.org>.
14. "Translation" is used here in several senses. First, in a molecular biological sense, found in any biology textbook, in which DNA "transcribes" RNA, and RNA "translates" a protein. Secondly, in a linguistic sense, in which some content is presumably conserved in the translation from one language to another (a process which is partially automated in online translation tools). Third, in a computer science sense, in which translation is akin to "portability," or the ability for a software application to operate across different platforms (Mac, PC, Unix, SGI). This last meaning has been elaborated upon by media theorists such as Friedrich Kittler, in his notion of "totally connected media systems." In this essay it is the correlation of the first (genetic) and third (computational) meanings which are of the most interest.
15. See Altschul, et al., "Basic Local Alignment Search Tool."
16. For instance, "blastn" is the default version, searching only the nucleotide database of GenBank. Other versions perform the same basic alignment functions, but with different relationships between the data: "blastp" is used for amino acid and protein searches, "blastx" will first translate the nucleotide sequence into amino acid sequence, and then search blastp, "tblastn" will compare a protein sequence against a nucleotide database after translating the nucleotides into amino acids, and "tblastx" will compare a nucleotide sequence to a nucleotide database after translating both into amino acid code.
17. Other bioinformatics tools websites, such as University of California San Diego's Biology Workbench, will also offer portals to BLAST searches, oftentimes with their own front-end. To access the Web-version of BLAST, go to <http://www.ncbi.nlm.nih.gov:80/BLAST>. To access the UCSD Biology Workbench, go to <http://workbench.sdsc.edu>.
18. A key differentiation in bioinformatics as a field is between research on "sequence" and research on "structure." The former focuses on relationships between linear code, whether nucleic acids/DNA or amino acids/proteins. The latter focuses on relationships between sequence and their molecular-physical organization. If a researcher wants to simply identify a test sample of DNA, the sequence approach may be used; if a researcher wants to know how a particular amino acid sequence folds into a three-dimensional protein, the structure approach will be used.
19. A query is a request for information sent to a database. Generally queries are of three kinds: parameter-based (fill-in-the-blank type searches), query-by-example (user-defined fields and values), and query languages (queries in a specific query language). A common query language used on the Internet is SQL, or structured query language, which makes use of "tables" and "select" statements to retrieve data from a database.
20. CGI stands for Common Gateway Interface, and it is often used as part of websites to facilitate the dynamic communication between a user's computer ("client") and the computer on which the website resides ("server"). Websites which have forms and menus for user input (e.g., email address, name, platform) utilize CGI programs to process the data so that the server can act on it, either returning data based on the input (such as an updated, refreshed splash page), or further processing the input data (such as adding an email address to a mailing list).
21. For more on the concept of "biomedia" see my "Data Made Flesh: Biotechnology and the Discourse of the Posthuman."
22. Though wet biological components such as the genome can be looked at metaphorically as "programs," the difference here is that in bioinformatics the genome is actually implemented as a database, and hence the intermingling of genetic and computer codes mentioned above.
23. The phrase "what a body can do" refers to Deleuze's reading of Spinoza's theory of affects in the Ethics. Deleuze shows how Spinoza's ethics focuses on bodies not as discrete, static anatomies or Cartesian extensions in space, but as differences of speed/slowness and as the capacity to affect and to be affected. For Deleuze, Spinoza, more than any other Continental philosopher, does not ask the metaphysical question ("what is a body?") but rather an ethical one ("what can a body do?"). This forms the basis for considering ethics in Spinoza as an "ethology." See Deleuze, Spinoza: Practical Philosophy, 122-30.
25. Crick's coding problem had to do with how DNA, the extremely constrained and finite genetic "code," produced a wide array of proteins. Among Crick's numerous essays on the genetic "code," see "The Recent Excitement in the Coding Problem." Also see Kay, Who Wrote the Book of Life?, 128-63.
25. For an example of this technique in action, see Celera's human genome report, Venter, et al., "The Sequence of the Human Genome."
26. For a broad account of the promises of molecular medicine, see Clark, The New Healers.
27. While genetic testing and the use of DNA chips are highly probabilistic and not deterministic, the way they configure the relationship between genetic and computer codes is likely to have a significant impact in medicine. Genetic testing can, in the best cases, tell patients their general likelihood for potentially developing conditions in which a particular disease may or may not manifest itself, given the variable influences of environment and patient health and lifestyle. In a significant number of cases this amounts to "leaving things to chance," and one of the biggest issues with genetic testing is the decision about the "right to know."
28. See Evans, et al., "Pharmacogenomics: Translating Functional Genomics into Rational Therapeutics." For a perspective from the U.S. government-funded genome project, see Collins, "Implications of the Human Genome Project for Medical Science."
29. This is, broadly speaking, the approach of "regenerative medicine." See Petit-Zeman, "Regenerative Medicine." Pharmacogenomics relies on bioinformatics to query, analyze, and run comparisons against genome and proteome databases. The data gathered from this work are what sets the parameters of the context in which the patient genome may undergo gene-based or cell therapies. The procedure may be as concise as prior gene therapy human clinical trials--the insertion of a needed gene into a bacterial plasmid, which is then injected into the patient. Or, the procedure may be as complex as the introduction of a number of inhibitors that will collectively act at different locations along a chromosome, working to effectuate a desired pattern of gene expression to promote or inhibit the synthesis of certain proteins. In either instance, the dry data of the genome database extend outward and directly rub up against the wet data of the patient's cells, molecules, and genome. In this sense data generate the body, or, the complex of genetic and computer codes establishes a context for recoding the biological domain.
30. Bergson discusses the concepts of the virtual and the possible in several places, most notably in Time and Free Will, where he advances an early formulation of "duration," and in The Creative Mind, where he questions the priority of the possible over the real. Though Bergson does not theorize difference in its post-structuralist vein, Deleuze's reading of Bergson teases out the distinctions Bergson makes between the qualitative and quantitative in duration as laying the groundwork for a non-negative (which for Deleuze means non-Hegelian) notion of difference as generative, positive, proliferative. See Deleuze's book Bergsonism, 91-103.
31. Deleuze's theory of difference owes much to Bergson's thoughts on duration, multiplicity, and the virtual. In Bergsonism, Deleuze essentially re-casts Bergson's major concepts (duration, memory, the "élan vital") along the lines of difference as positive, qualitative, intensive, and internally-enabled.
32. There are a number of efforts underway to assemble bioinformatics databases centered on these processes of regulation. BIND (Biomolecular Interaction Network Database) and ACS (Association for Cellular Signaling) are two recent examples. However, these databases must convert what are essentially time-based processes into discrete image or diagram files connected by hyperlinks, and, because the feasibility of dynamic databases is not an option for such endeavors, the results end up being similar to sequence databases.
33. As Susan Oyama has noted, more often than not, genetic codes are assumed to remain relatively static, while the environment is seen to be constantly changing. As Oyama states, "if information . . . is developmentally contingent in ways that are orderly but not preordained, and if its meaning is dependent on its actual functioning, then many of our ways of thinking about the phenomena of life must be altered" (Oyama 3).
Works Cited
Abola, E.E., et al. "Protein Data Bank." Crystallographic Databases. Ed. F.H. Allen, G. Bergerhoff, and R. Sievers. Cambridge: Data Commission of the International Union of Crystallography, 1987. 107-32.Aldridge, Susan. The Thread of Life: The Story of Genes and Genetic Engineering. Cambridge: Cambridge UP, 1998.
Altschul, S.F., et al. "Basic Local Alignment Search Tool." Journal of Molecular Biology 215 (1990): 403-410.
Bairoch, A., et al. "The SWISS-PROT Protein Sequence Data Bank." Nucleic Acids Research 19 (1991): 2247-2249.
Baxevanis, Andreas, et.al., eds. Bioinformatics: A Practical Guide to the Analysis of Genes and Proteins. New York: Wiley-Liss, 2001.
Bergson, Henri. Time and Free Will. New York: Harper and Row, 1960.
---. The Creative Mind. Westport, CT: Greenwood, 1941.
Chang, A.C.Y., et al. "Genome Construction Between Bacterial Species in vitro: Replication and Expression of Staphylococcus Plasmid Genes in Escherichia coli." Proceedings of the National Academy of Sciences 71 (1974): 1030-34.
Clark, William. The New Healers: The Promise and Problems of Molecular Medicine in the Twenty-First Century. Oxford: Oxford UP, 1999.
Cohen, Stanley, et al. "Construction of Biologically Functional Bacterial Plasmids in vitro." Proceedings of the National Academy of Sciences 70 (1973): 3240-3244.
Collins, Francis. "Implications of the Human Genome Project for Medical Science." JAMA online 285.5 (7 February 2001):
Crick, Francis. "The Recent Excitement in the Coding Problem." Progress in Nucleic Acids Research 1 (1963): 163-217.
Dayhoff, Margaret, et al. "A Model for Evolutionary Change in Proteins." Atlas of Protein Sequences and Structure 5.3 (1978): 345-358.
Deleuze, Gilles. Bergsonism. New York: Zone, 1991.
---. Spinoza: Practical Philosophy. San Francisco: City Lights, 1988.
Deleuze, Gilles, and Felix Guattari. A Thousand Plateaus. Minnesota: U of Minnesota P, 1987.
Emmett, Arielle. "The State of Bioinformatics." The Scientist 14.3 (27 November 2000): 1, 10-12, 19.
Evans, W.E., et al. "Pharmacogenomics: Translating Functional Genomics into Rational Therapeutics." Science 286 (15 Oct 1999): 487-91.
Foucault, Michel. "The Birth of Biopolitics." Ethics: Subjectivity and Truth. Ed. Paul Rabinow. New York: New Press, 1994. 73-81.
---. The Birth of the Clinic: An Archaeology of Medical Perception. New York: Vintage, 1973.
Gibas, Cynthia, and Per Gambeck. Developing Bioinformatics Computers Skills. Cambridge: O'Reilly, 2000.
Goodman, Nathan. "Biological Data Becomes Computer Literate: New Advances in Bioinformatics." Current Opinion in Biotechnology 31 (2002): 68-71.
Ho, Mae-Wan. Genetic Engineering: Dream or Nightmare? London: Continuum, 200X.
Holley, R.W., et al. "The Base Sequence of Yeast Alanine Transfer RNA." Science 147 (1965): 1462-1465.
Howard, Ken. "The Bioinformatics Gold Rush." Scientific American (July 2000): 58-63.
James, Rob. "Differentiating Genomics Companies." Nature Biotechnology 18 (February 2000): 153-55.
Kay, Lily. "Cybernetics, Information, Life: The Emergence of Scriptural Representations of Heredity." Configurations 5.1 (1997): 23-91.
---. Who Wrote the Book of Life? A History of the Genetic Code. Stanford: Stanford UP, 2000.
Kevles, Daniel, and Leroy Hood, eds. The Code of Codes: Scientific and Social Issues in the Human Genome Project. Cambridge: Harvard UP, 1992.
Kittler, Friedrich. Gramophone, Film, Typewriter. Stanford: Stanford UP, 1999.
MacKenzie, C.E. Coded Character Sets: History and Development. Reading, MA: Addison Wesley, 1980.
Oyama, Susan. The Ontogeny of Information: Developmental Systems and Evolution. Durham: Duke UP, 2000.
Palsson, Bernhard. "The Challenges of in silico Biology." Nature Biotechnology 18 (November 2000): 1147-50.
Persidis, Aris. "Bioinformatics." Nature Biotechnology 17 (August 1999): 828-830.
Petit-Zeman, Sophie. "Regenerative Medicine." Nature Biotechnology 19 (March 2001): 201-206.
Ridley, Matt. Genome. New York: Perennial, 1999.
Sanger, Fred. "The Structure of Insulin." Currents in Biochemical Research. Ed. D.E. Green. New York: Wiley Interscience, 1956.
Saviotti, Paolo, et al. "The Changing Marketplace of Bioinformatics." Nature Biotechnology18 (December 2000): 1247-49.
Stein, Lincoln. "How PERL Saved the Human Genome Project." Perl Journal <http://www.tpi.com>.
Thacker, Eugene. "Data Made Flesh: Biotechnology and the Discourse of the Posthuman." Cultural Critique 53 (forthcoming 2003).
Venter, Craig, et al. "The Sequence of the Human Genome." Science 291 (16 February 2001): 1304-51.
